Computer vision overview
Tier 0 — Edge & Mobile-Optimized Detectors
Runs on phones, drones, Raspberry Pis, embedded cameras.
They detect a fixed set of classes
-
YOLO-NAS (Tiny) — NAS-discovered architecture with built-in quantization awareness
-
MobileNet-SSD — lightweight CNN backbone designed for mobile inference
-
EfficientDet — compound-scaled detector balancing resolution, depth, and width
-
YOLO11-N / YOLOv8-N — nano-sized YOLO variants for edge deployment
-
RF-DETR Nano — smallest RF-DETR variant, ~100 FPS on NVIDIA T4


Tier 1 — Real-Time Specialist Detectors
More accurate, run on GPU's
They detect a fixed set of classes
-
RF-DETR (Base / Medium / Large / 2XL) — transformer-based, first real-time model to exceed 60 AP on COCO, NMS-free
-
YOLOv12 — latest YOLO with area attention and R-ELAN blocks
-
YOLO11 / YOLOv8 — widely adopted anchor-free single-stage CNN detectors
-
D-FINE — real-time transformer detector competitive with RF-DETR at larger sizes
-
LW-DETR — lightweight DETR with plain ViT backbone
-
RT-DETR — first DETR to match YOLO speeds, from Baidu

√Tier 1.5 — Promptable Segmentation Models
don't classify, segments (cuts out objects from picture). Typically paired with a detector to get both detection and pixel-perfect masks.
-
SAM 2 (Segment Anything Model 2) — universal promptable segmentation from Meta, supports images and video
-
SAM (original) — the foundational "segment anything" model
-
HQ-SAM — high-quality variant for fine-grained mask edges
-
FastSAM — CNN-based reimplementation of SAM for faster inference
-
EfficientSAM — distilled SAM variant for resource-constrained environments
Tier 2 — Open-Vocabulary Detection Models
Aaccept text or visual prompts to detect arbitrary objects zero-shot — no retraining needed. Slower than Tier 1, but can find anything you describe.
-
DINO-X (Pro / Edge) — SOTA open-world detector from IDEA Research, 56 AP zero-shot on COCO
-
GroundingDINO 1.5 / 1.6 — text-prompted detection combining DINO with language grounding
-
OWLv2 (Open-World Localization) — Google's open-vocabulary detector built on ViT
-
Detic — vocabulary-expanded detector using image-level supervision
-
YOLO-World — open-vocabulary extension of YOLO architecture


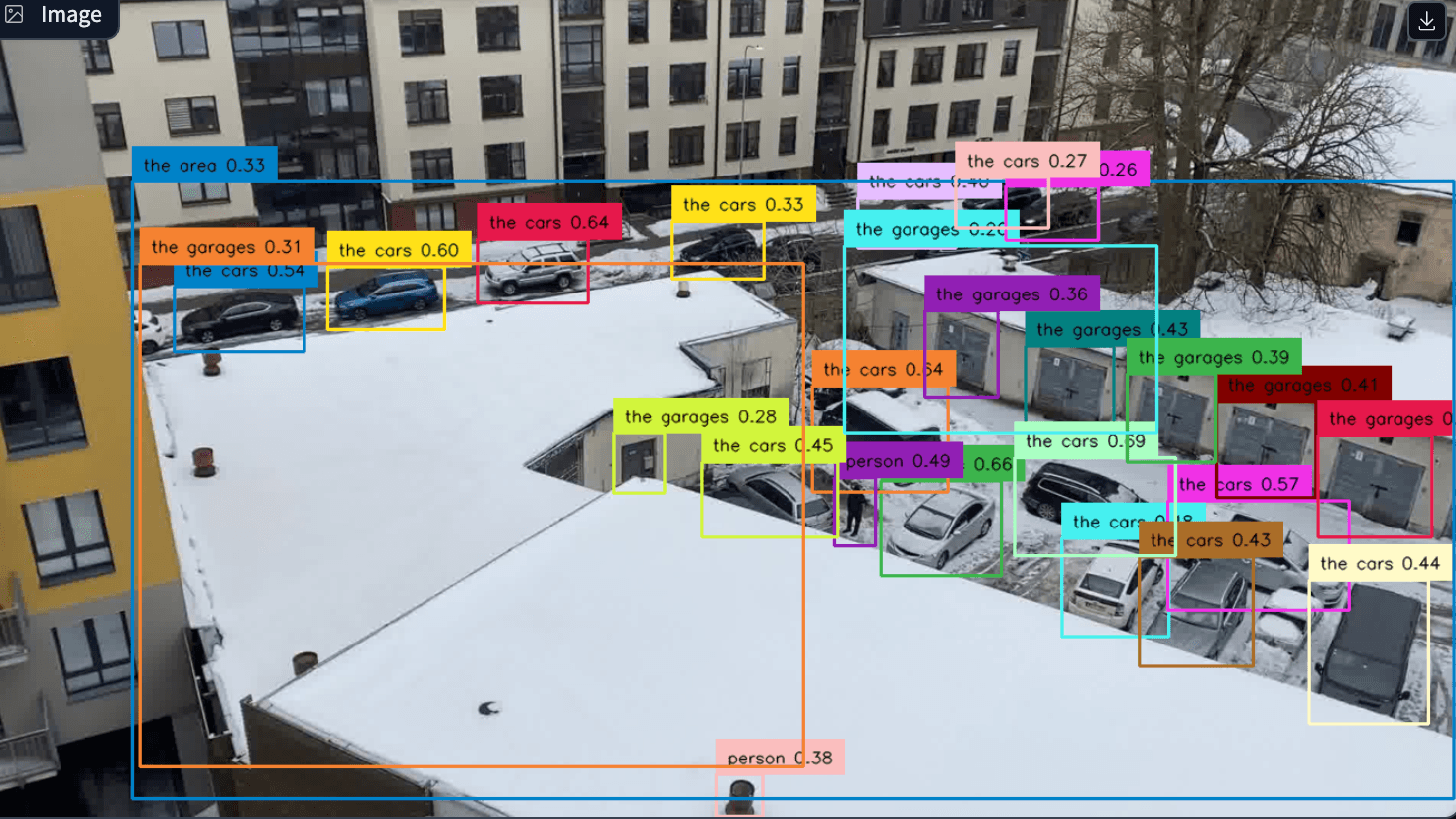
Tier 3 — General-Purpose Vision-Language Models (VLMs)
Massive model. Captioning, reasoning, document parsing, and agentic tasks. Slow and expensive.
-
Qwen2.5-VL / Qwen3-VL — Alibaba's open-source VLM family, strong grounding and spatial awareness
-
GPT/Gemini/Claude
-
InternVL 2.5 — open-source VLM with competitive detection grounding
-
Florence-2 — Microsoft's unified vision foundation model supporting detection, captioning, and grounding


